Rosso提供サービスとお客様ニーズ

人手を減らし、利用しやすいデータへ
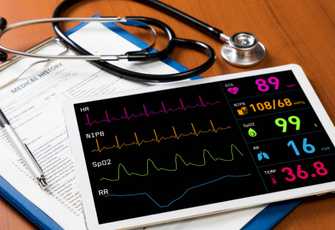
救急の現場では傷病者の状態や、バイタルモニター、お薬手帳の内容が口頭で伝達され、その情報を電子カルテに手入力で行うことがあります。 この作業には、以下の課題がありました。
- 手入力は手間がかかる
- 誤入力の可能性がある
- フリーフォーマットの場合、情報を共有しづらい
- 入力規則が整っていない場合、蓄積したデータを調査・研究に使いにくい
OCR で文字を読み取り、定型化されたフォーマットに情報を蓄積すると、これらの課題を解決することができます。
これらの課題は、OCR で文字を読み取り、定型化されたフォーマットに情報を蓄積すれば解決することができます。
しかし、一般的な OCR をそのまま医療現場に導入しても、精度が良くないことがあります。
OCRは、そのまま導入しても精度が上がらない
医療従事者向けOCRでは、以下のような要因があったため、工夫が必要でした。
- 斜めからの撮影
- 目標物以外の機材・人物の映り込み
- 歪んだ文字列の認識が必要
- 1文字単位での文字検出が必要
- ノイズ・背景の影響
- 独特なフォント
医療従事者向け専用 OCR の開発
上記要因に対応した医療従事者向け専用 OCR を開発しました。 システム詳細について、OCR を構成する技術である「セグメンテーション・台形補整」「文字検出」「文字認識」ごとに説明します。
1.セグメンテーション・台形補整
斜めからの撮影に対応するため、対象物(バイタルモニターやお薬手帳)を真正面から捉えた画像を生成します。 また、補整の過程で、機材・人物の映り込みにも対応します。
1-1.対象物の枠を大まかに検出(下図の真ん中参照)
OCR対象となる箇所(バイタルモニターやお薬手帳)を検出します。この処理をセグメンテーションと言います。 セグメンテーションは、10 ~ 100 枚程度のサンプル写真を用いて、AIに対象物を学習させて行います。
1-2.真正面からの画像へ変換(下図の右参照)
対象物を真正面から捉えた画像に変換します。この処理を台形補整と言います。古典的な画像処理技術で可能です。 対象物全体が写っている写真は問題ないのですが、機材・人物が写りこんだ場合、対象物全体が写真に納まっていないことがあります。 このような写真をセグメンテーション処理すると、結果が歪になります。対象物の形を推測し、セグメンテーション結果を補整しながら、台形補整を行うように工夫します。

2.文字検出
台形補整した画像から、文字を検出します。 一般の文字検出をそのまま使用しただけでは難しい「歪んだ文字列」と「1文字単位での文字検出」に対応する必要があります。
2-1.歪んだ文字列への対応
お薬手帳を手に持って撮影した場合などに、文字列が歪む場合があります。そのため、歪んだ文字列に対応した文字列認識モデルを使用します。 また、歪んだ文字列の場合、単語や文章を一続きとして認識できない場合があります。そのため、歪みを考慮した後処理を加えて、一続きとして認識できるようにします。 さらに、モニタや手帳に表構造がある場合は、別処理で構造を抽出し、それを意識した文字列検出を行えるようにします。
2-2.1文字単位での文字検出
一般的な文字検出モデルは、画像に写った文章や単語の検出をメインとしており、独立した1文字単位や短い文字列の検出には弱いです。 しかし、バイタルモニターやお薬手帳には、独立した一文字が重要な意味を持つ場合があります。 以下の技術を併用することで、1文字単位の見逃しを減らすことが可能です。
- 1文字単位の文字検出モデル
- 輪郭検出
- テンプレートマッチング
3.文字認識
自動生成した文章を基に、文字をAIに学習させます。
このとき、ノイズを加えたり、背景を変えたりした画像も学習させ、ノイズ・背景の影響を抑えたモデルを作成します。
また、独特なフォントには数枚の生サンプルを用意し、AIに学習させます。

導入効果
汎用 OCR と比較し、以下のケースで文字認識精度が高くなりました。
- モアレ(下図参照)や点線などのノイズ混じりの文字列
- 非常に狭い行間や文字間隔の文字列、または横幅を極端に狭めた文字列
結果として、お薬手帳 OCR では平均 3 秒、95%の精度(完全な正答をした枚数/テスト枚数)で処方された薬品名を出力しました。
また、バイタルモニタ OCR では平均 1.7 秒、こちらも 95%の精度(完全な正答をした枚数/テスト枚数)を出力しました。